
4 min. read
Create A Backup of Passbolt Data With A Bash Script
Passbolt has created a bash script that you can use to perform regular backups of your data in Passbolt. Get started with this easy-to-follow guide.

Users sometimes ask about setting up passbolt with Disaster Recovery (DR) in mind. This post presents one option available for DR. But, it should be noted that since every environment and individual's needs will vary, the details in this guide may not be entirely applicable to your case. Read on to discover a warm DR setup, its constraints, and what alternatives are available.
First, let’s gather some supplies. A couple things you’ll need if you want to reproduce the DR setup outlined:
Since this is a warm DR configuration, you’ll need to perform steps on two different servers. For everyone’s sanity, the current passbolt instance will be referred to as Alpha, while the spare server – the failover instance – will be referred to as Beta. Here’s a rough idea of what you’ll be doing:
This demonstration will show how to complete the actual setup of the DR environment. You’ll see how the replication actually works and what you can expect during a failover.
Your first step will be to SSH into your Alpha server to edit your /etc/mysql/my.cnf file. Add the following:
[mariadb]
log-bin
server_id=1
log-basename=master1
binlog-format=mixedAs you can see here:

Provided that you’re running it on Debian 11, you’ll also need to make sure that the bind-address in /etc/mysql/mariadb.conf.d/50-server.cnf allows for remote connections.
In this example, 0.0.0.0 is used to allow both remote and local connections since passbolt is being run locally and the Beta server is run remotely:

At this point, you will need to reboot MySQL on your Alpha server for these modifications to be applied:
sudo systemctl restart mysqlNext, a replication user needs to be set up so the Beta server can communicate with this database. So, access your MySQL server to continue with the setup:
sudo mysql -u root -pThen create your user:
CREATE USER 'replication_user'@'%' IDENTIFIED BY 'bigs3cret';
GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%';Note that this configuration enables the replication_user to connect from any IP address. To minimise risk, consider replacing the % with the IP address of your Beta server. It’s also advisable to change the password from “bigs3cret” to something more secure.
With step 1 complete, the Alpha server is ready to function as the Primary database for a Replica.
Now you can SSH into your Beta server and start prepping it. Your approach would mostly be to follow the passbolt guide to migrate to a new server, with a twist. For now, the backup step will be postponed for later.
Essentially, the following steps will need to be followed from the migrate guide:
A domain will need to be specified as part of this. There are two option here:
There’s more information about this in the “Limitations and Considerations” section below.
Once you’ve completed the above, the output should be the instructions to finish set up in the web browser as seen here:
But you're not going to do that, you won't need to, as you'll be importing the database and configuration files from the Alpha server. For now you're done on the Beta server.
So this step will be a little more complicated than just a standard backup. For this step you will need two SSH sessions open with your Alpha server.
In one Alpha server session, you’ll need to log in to MySQL:
sudo mysql -u root -pAnd run the following in MySQL:
FLUSH TABLES WITH READ LOCK;
SHOW MASTER STATUS;The output should look something like this:
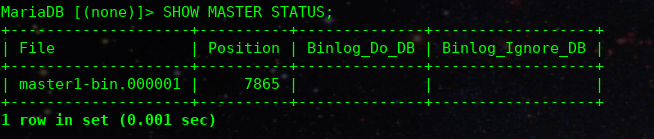
You should save the File and Position somewhere for later. You’ll need to keep a record of these.
Now for the other Alpha server SSH session. In this session, you’ll need to take a backup of your passbolt instance. There are two options:
Once you have the backup, you’ll need to run this command in the MySQL session on your Alpha server:
UNLOCK TABLES;Then you can close the MySQL connection on the Alpha server.
Next, copy the backup from the Alpha server to the Beta server.
Once the backup has been copied to the Beta server, you need to SSH into it. Then process to migrate the data using the step from the migrate to a new server guide. You can skip steps 6 and 7 in this guide, as you should already be using the latest version of passbolt.
On the Beta server, a minor change to the MySQL configuration file is required to run it as a Replica database. In the /etc/mysql/my.cnf file, you need to assign a server_id that’s different from the one used on the Alpha server (and any other Replica).
For the purpose of this demonstrations, the value is set as 2:

With that change, it’s time to reboot MySQL on the Beta server:
sudo systemctl restart mysqlYou are now ready to actually connect the Beta server as a Replica of the Alpha server. To do this, you need to log into MySQL on the Beta server:
sudo mysql -u root -pThen you’ll need to run something similar to this to establish the connection:
CHANGE MASTER TO
MASTER_HOST='10.103.209.56',
MASTER_USER='replication_user',
MASTER_PASSWORD='bigs3cret',
MASTER_PORT=3306,
MASTER_LOG_FILE='master1-bin.000001',
MASTER_LOG_POS=7865,
MASTER_CONNECT_RETRY=10;There are a few changes here to get this working. Let’s break down the important ones:
Now, all you need to do is start the replication process on the Beta server in MySQL:
START SLAVE;To confirm everything is working and running smoothly, you can run this:
SHOW SLAVE STATUS \GRunning that should output something similar to this:
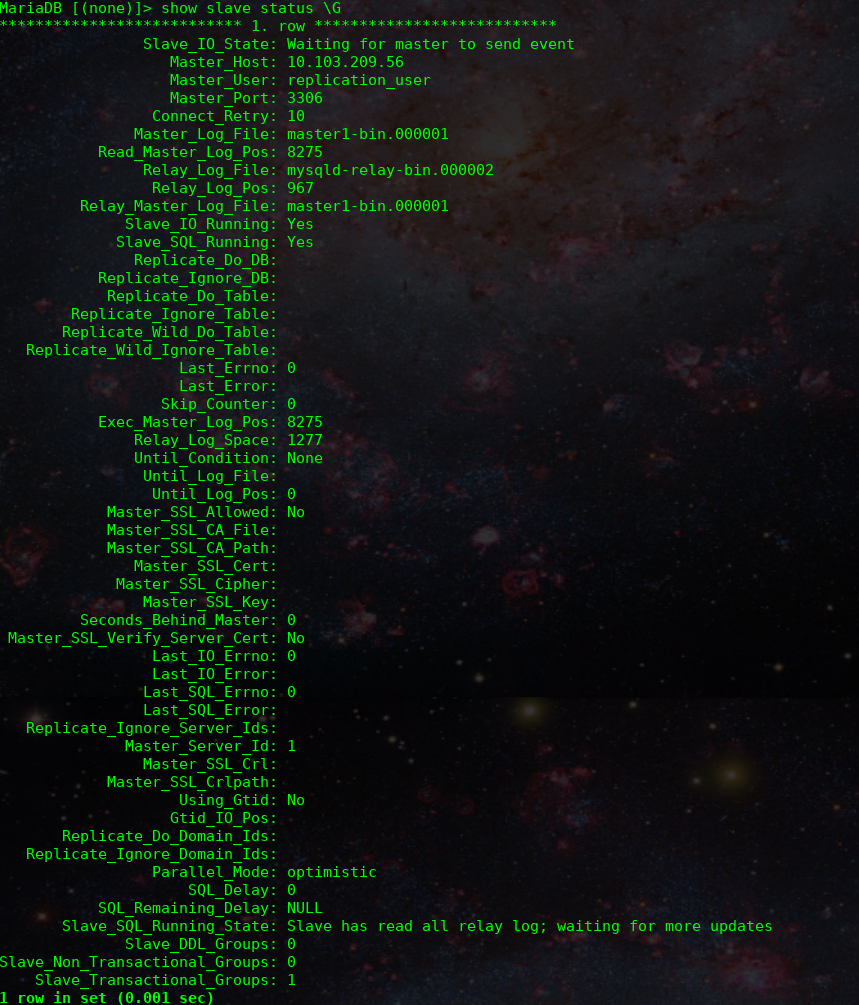
The two most important lines are:
Slave_IO_Running: Yes
Slave_SQL_Running: YesIf you have that output then your Disaster Recovery is completely setup!
Here are some other things to show you what this looks like and show that it’s working.
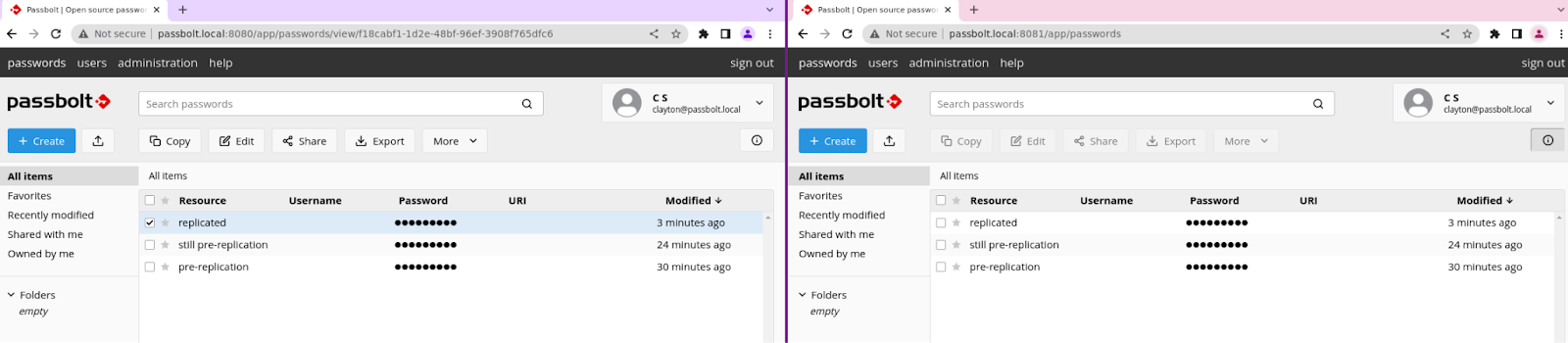
Here you see that both databases have the same number of resources:
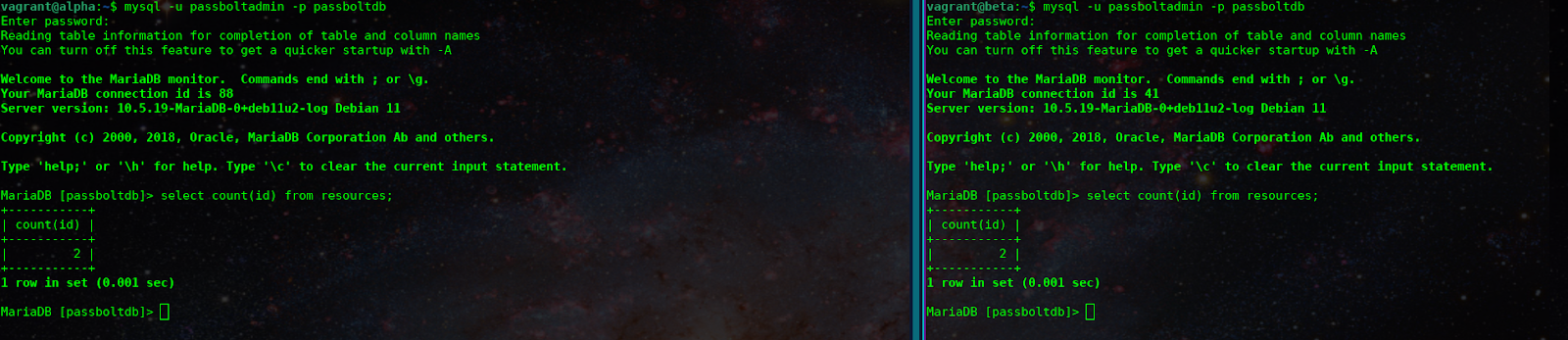
And here you can see that these are hosted locally on different ports. The secrets are replicating from the Alpha server to the Beta server:
This is a DR setup, so you may want to stop the web server on your Beta instance, so that no one accidentally makes changes there, instead of on the Alpha server. You can do this by running the following on your Beta server:
sudo systemctl stop nginxLike with most things, there are going to be some limitations to this setup and some things to consider before deciding if this is the route you want to take for your DR.
This DR setup only replicates the database. A majority of your settings are stored in the database, so this shouldn’t post a problem. The catch, however, is that if you modify your passbolt.php file to change a setting that’s not in the database, it won’t transfer over. And if you update your GPG keys, it’s important to make sure that the new keys are imported to your Beta server or none of the settings in your database will be available.
This method will essentially double the resource costs. Running two servers instead of one can add up over time and it’s something you should be aware of. Backups, Disaster Recovery, and High Availability are all things that do add to the total cost of self hosting. So, It all depends on how much you’re willing to spend on maintaining a DR setup and what feels right for your needs. If you regularly check your backups and feel confident that you can quickly recover your data, you may not need Disaster Recovery.
This DR setup shouldn’t be used as a replacement for taking backups. Any changes that are made to your production system will be quickly replicated to your DR, whether positive or negative. If your main instance goes down this sort of setup will allow you to switch over relatively quickly (depending on what method you use). But, this won’t protect against any deletions of data or accidents.
Throughout this demonstration, there were a lot of assumptions made about your environment. For instance, it assumes that you’ve installed via the package and that your database runs on the same server as your passbolt instance. It’s likely that modifications will be needed to make this guide suitable for your environment.
Earlier, the guide mentioned that you’ll need to decide on the domain name for your DR instance. Using the same domain name as your main instance will require you to switch DNS records if you need to fail over. Depending on your environment, this can range from being trivial to being a challenge. Taking this approach should allow users to log directly into your DR instance once the DNS records are changed.
If you use a different domain name for your DR instance, you can avoid dealing with DNS changes during a failover. But, when visiting the DR instance, users will need to perform account recovery steps using their emails and recovery kits. This might not be a concern for your environment or it could pose issues for end users. Whatever you choose, this trade-off must be considered when choosing the setup that works best for your needs.
This guide requires some prior knowledge of databases, which generally goes further than beginner-level topics. While getting the system up and running may only require basic understanding, maintaining it and troubleshooting could require a higher level of proficiency. Ensure that you are comfortable and willing to properly set it up and keep it working when you need it.
Now that you have a warm DR setup, here’s what you should do next:
Naturally, it’s important to test the DR to guarantee it’s functioning properly in your environment. Similar to backups, testing it when it’s not needed can help prevent potential issues when it is.
You’ll likely want to include this DR in your monitoring. Adding monitoring will make sure that the server is still running and the replication is flowing smoothly. Afterall, you don’t want to find out that the replication stopped a week before you had to fail over.
The instructions won’t be included here, but it’s currently recommended to use GTIDs for your replication. Making it even more important that nginx was stopped on the Beta server to ensure that replication doesn’t fail.
With DR setup, you may be wondering how to transform it into a High Availability setup. This will be covered in another blog post with comprehensive details and a guide on configuring HA. However, it won’t follow the same configuration as this post. You can build this DR configuration on an existing passbolt installation, but the HA setup will focus on building one from scratch.
If you have any questions or feedback, join the passbolt community.
4 min. read
Passbolt has created a bash script that you can use to perform regular backups of your data in Passbolt. Get started with this easy-to-follow guide.

5 min. read
Passbolt is celebrating reaching 4,000 stars on the API repository and it’s all thanks to contributors like you! Take a look at the statistics behind this achievement.